构造分析样本
对分析数据进行选取,分析预测情况,分析样本数据:
1)针对业务使用会议用户的活跃程度,统计14天之后的使用情况;
2)对数据分析进行曲线分析,特别是根据14天不使用的账号和14天使用频率极高的会议用户抽取为活跃会议用户,并打上标签,方便后续使用;
3)通过曲线,样本账号是观察在8周之前的行为数据,按照每个周的频率进行统计,同时加入包括数据图像的特征属性。
关于模型待选变量的选择标准主要从四个方面加以考虑:
. 变量的预测能力
. 变量的稳定性
. 变量与业务的趋势一致性
. 变量间的相关性
1) 变量的预测能力
在预测方面的能力的大小,选择合适的计算信息值的IV(Information Value)来量度。IV值可以体现两方面:预测变量和判断分组数据的依据。
IV的定义和熵(平均信息量)的定义很相似:
IV = ∑((p_non-eventattribute – p_eventattribute) * woeattribute)
一般情况下,使用支持向量机的分析有以下情况:
本文采用分析数据方法和scipy框架对数据进行分析,最终用 pillow 库来实现交互界面。在做设计的过程中,了解了很多大数据分析方法,锻炼了自主学习的能力,使用最新的知识对数据进行分析,更好的将数据分析应用到实际应用中去。文章对数据移动会议用户进行流失情况的分析,得出影响会议用户使用的多种因素。使用第三方库抽取会议跟踪数据,本文使用的是会议移动设备,对会议用户的使用属性和行为数据进行分析挖掘,建立预测会议用户模型。
目 录
第一章 绪 论 1
第二章 预测模型构建 4
第三章 预测模型构建 5
3.1业务理解 5
3.1.1业务现状 5
3.1.2问题定义 5
3.2 流失行为 6
3.2.1. 会议用户流失行为定义 6
3.2.2 滚动使用分析 6
3.3 构造分析样本 7
3.4. 检验数据质量 8
第四章 建模分析 9
4.1. django的选择 9
4.2. 抽样与过抽样 9
4.3. 数据探索与修改 9
4.3.1. 变量离散化 10
4.3.2. WOE(Weights of Evidence)值计算: 10
4.3.3. 变量选择 10
4.4. 建模 12
第五章 模型评价 13
1) 是否达到符合应用要求的准确性水平 13
2) 是否具有较高的稳定性 13
3) 是否简单 13
4) 是否有意义 13
第六章 模型应用 14
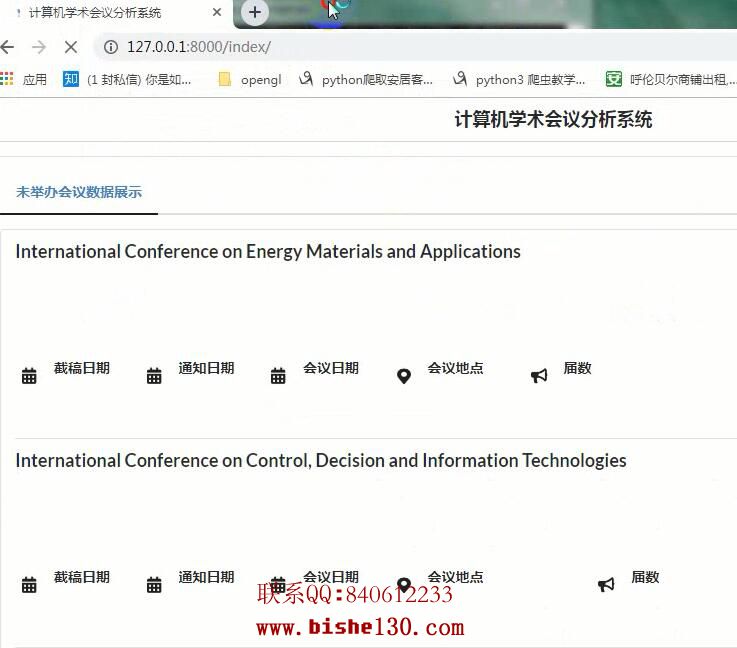
1) 用未举办的会议的重要因素 14
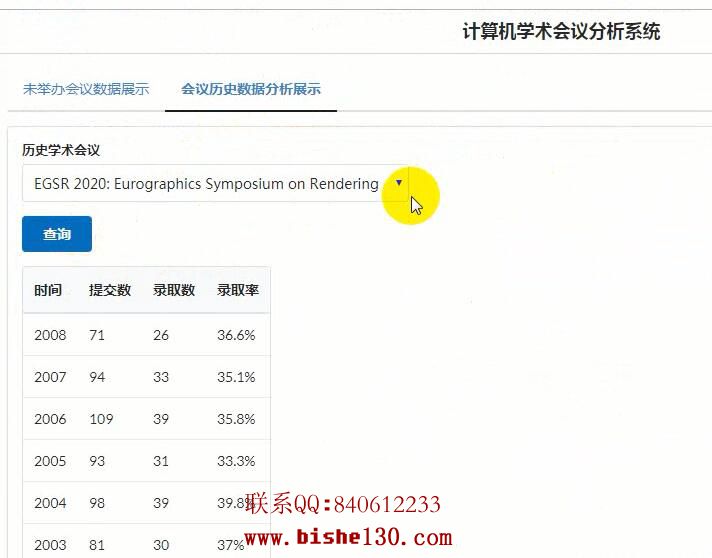
2) 用会议历史数据分析可能性 15
3)优化研究方向 15
第七章 结语 15
致谢 17
参考文献 18